國企系「人工智慧與商業應用」課程專題演講:《機器學習要學什麼》
國際企業學系暨研究所
撰文者/國際企業學研究所 李哲柔
本系簡睿哲老師「人工智慧與商業應用」課程中邀請核能研究所曾繁斌副工程師蒞臨演講,本次演講命題為《機器學習要學什麼》,結合上次演講中所提及的人工智能,本次演講著重在機器學習端,向同學介紹機器學習的內容,且提點了data preprocessing, linear regression, logistic regression, SVM, decision tree, ensemble learning, PCA and K-means等概念。

因為疫情關係,此次演講中與首次一樣是線上模式,講師先與同學們回顧第一次演講提及的AI學習方式:從定義問題、數據準備、建立AI模型、結果評估到模型部屬。因此,找出題目的 X與 Y變得至關重要,因著一開始的定義問題過後便會發現需求,進而建構場景,且去找到相對應需要的數據。為了引出後續的建模概念,講師先向學員介紹了一些統計的概念,包含定義資料中心趨勢的平均數,以及資料分散程度的標準差,且向大家從數據缺失原因的問題帶出第一個應用,以「缺資料」的例題引發學員們解決問題的思維,最後導引到缺值原因除了有不存在該值、無法取得、使用者不願意提供等等外,也有相對應的處理方式如維持缺失值、以代表值填補、用其他變數作預測等等,學員們遇到時並不用太緊張。
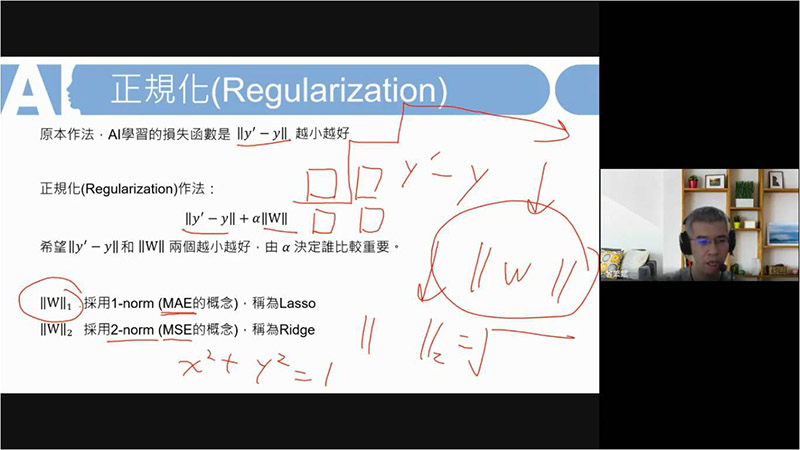
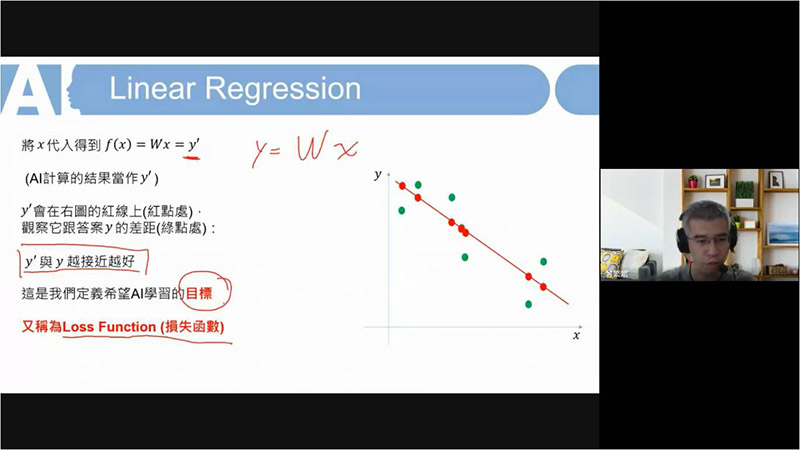
除了缺失值的概念外,接著有normalization 與 encoding的概念,以圖示和「成績」的範例向同學們介紹了常態分部的概念,介紹標準化、非線性轉換、one-hot encoding等等的資料處理概念。不過,因著許多資料通常會需要用到迴歸的處理,因此講師也與同學分享linear regression當中的batch, epoch等概念,且結合到AI的學習方式與學習率的探究,更結合上次演講中的overfitting與學習曲線概念,實際讓學員們研讀相關程式寫法。除了batch, epoch概念之外,另外也與學員們介紹了Lasso與Ridge的使用用途與時機:norm限制器的迴歸。而迴歸當中,又以logistic regression做為此演講中一大重點介紹,除了Loss function的介紹外,也帶出matrix的概念與應用,更是進深到svm (support vector machine)的學習。
在進行一些較深的專有名詞概念介紹後,演講的最後,講師也提到decision tree和其他AI技術的概念:決策樹因為是一個if-then規則的演算法,因此沒有距離觀念,通常用於分類,而其他技術也有包含遷移學習、GAN、強化學習、自我監督式學習、主動學習、連續學習、聯合學習等等。
透過曾講師此次精彩的演說,學員們更能了解AI學習的不同面向,且對專有名詞的基本概念有些基礎的了解,可用於未來進到職場相關領域中的基礎溝通,不至於再對科技發展名詞「霧煞煞」。